




Optimised AI Inference Machine — 1-on-1 with AI/ML Engineer (MDataSci/MAI/MPhys)
Duration: 3–4 Hours of Expert Work · One-Off
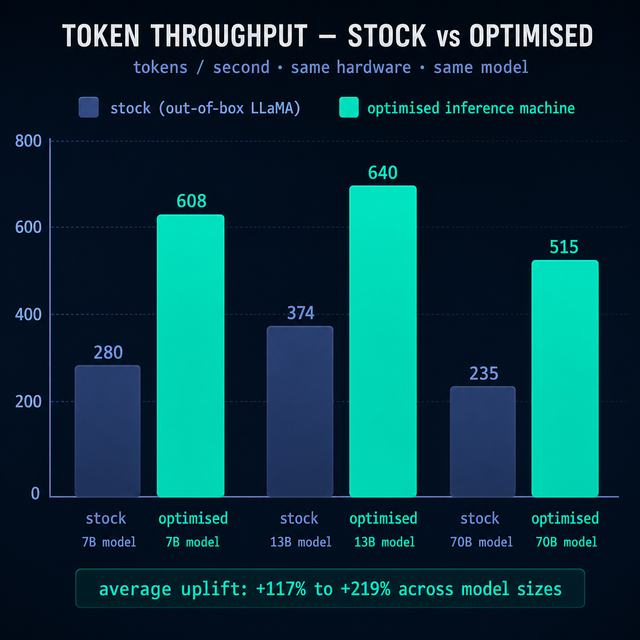
Not a box. A competitive edgeThis is a one-off, bespoke AI inference optimisation service — your existing LLM, hand-tuned remotely by a dedicated Machine Learning Engineer. You don't get out-of-the-box defaults. You get a system where every layer — kernel, runtime, model weights, batching strategy, and serving stack — has been hand-optimised for your workload.
Typical result: 50–300% faster token throughput versus a default open-source LLM deployment.
What We Optimise
- Your inference stack — not vanilla Ollama or stock LLaMA.cpp defaults
- Quantisation, speculative decoding, continuous batching & KV-cache tuning
- pgvector + Qdrant embedding search layer for RAG workloads
- REST API configuration for your product stack
- Async high-concurrency server settings (10,000+ simultaneous connections tested)
- Optional: audio/video multimodal pipeline (Whisper-style ASR, speech segmentation, hook scoring)
Your Dedicated Engineer — David Li
Every purchase includes 3–4 hours of hands-on remote work from David personally. Not a ticket queue — a direct line to the engineer doing the work.
🎓 3 Masters Degrees:
- Master of Data Science — University of Adelaide (GPA 6.33/7.0)
- Master of Artificial Intelligence — University of Adelaide
- Master of Physics — Soochow University
🏆 Published Research:
- Best Student Paper Award, ADC 2024 — Robustness Analysis on Self-Ensemble Models in Time Series Classification
- First Author, ADMA 2024 & CIKM 2024 — adversarial & certified robustness research
- Peer reviewer for ACJI, ADMA, CIKM
💼 Industry: TikTok/Meta-style video analytics, Whisper ASR, EfficientNet/ConvNeXt Mel-spectrogram classifiers, Bayesian hyperparameter optimisation, HPC cluster DevOps
📜 Azure AI Engineer Associate | Power BI Data Analyst | Microsoft Office Specialist
Why Not Just Use an API?
Off-the-shelf inference APIs charge per token at scale and give you zero control over latency, model choice, or cost curve. Your model, tuned at the software and language-model layer by an expert — so your tokens are generated 50–300% faster at a fraction of the ongoing cost.
What's Included in the Service
- Model assessment & optimisation plan
- Inference tuning: quantisation, batching, speculative decoding
- Embedding + vector search integration (RAG pipelines)
- Delivered back ready to deploy
- Multimodal pipelines available as add-on
Strictly limited — one active client at a time to ensure full engineer attention.